Google Cloud Functions: How to Automate Data Ingestion Pipeline Within GCP

Introduction
In the world of data, getting your hands on the data is the first, most critical step. Manually downloading and uploading files every day is slow, prone to errors, and simply doesn’t scale. The solution is automation, and Google Cloud Platform (GCP) offers a powerful, serverless tool to make it happen.
This guide will walk you through building a fully automated, serverless data ingestion pipeline. We’ll take a real-world COVID-19 dataset, write a Python script to fetch it, and deploy it as a Cloud Function which automatically loads the latest data into BigQuery every single day.


To effectively execute this task, we will use the following tech stack:
- Automation: Google Cloud Functions
- Data Lake / Staging: Google Cloud Storage (GCS)
- Data Warehouse: Google BigQuery
- Scheduling: Google Cloud Scheduler
- Language: Python
To be able to follow me and get hands-on on this project, you these will be the prerequisites
- A Google Cloud Platform account with billing enabled.
- Basic knowledge of Python
Now, to have a clearer understanding of the tech stack we chose for the automation, let’s find out why we chose Google Cloud Function
Why Serverless Automation with Cloud Functions
A Cloud Function is a lightweight, serverless compute service that runs your code in response to an event—like an HTTP request or a schedule.
Here are the key benefits:
- No Servers to Manage: You only upload your code, and Google Cloud Function handles the rest. You don’t need to provision or manage a virtual machine.
- Pay Per Use: You’re only charged for the milliseconds your code is actually running, making it incredibly cost-effective for tasks that run infrequently, like a daily ingestion job.
- Scalability: Google automatically scales the resources needed to run your function, whether it’s triggered once a day or a thousand times a minute.
This makes Cloud Functions the perfect choice for building efficient, low-cost automation for data pipelines.
Set Up Your GCP Environment
Before we write any code, we need to prepare our cloud environment by creating a storage bucket for our raw data and a BigQuery dataset to house the final table.
Create a Cloud Storage Bucket
This bucket will act as a staging area or “data lake” where we temporarily store the CSV file before loading it into BigQuery. Click here for a complete article on how to setup Cloud Storage and ingest data into the bucket.
- In the GCP Console, navigate to Cloud Storage > Buckets.
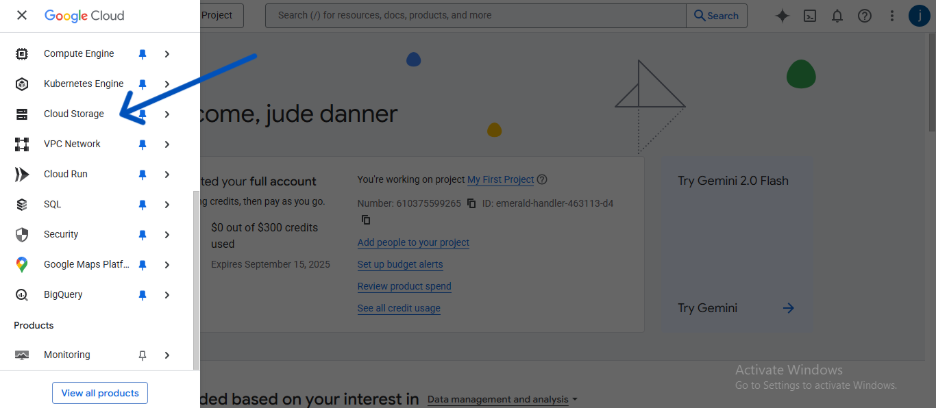
- Click CREATE and give your bucket a globally unique name (e.g., dekings-covid-data-pipeline). I gave a much more detailed explanation of how to do this in a different article.
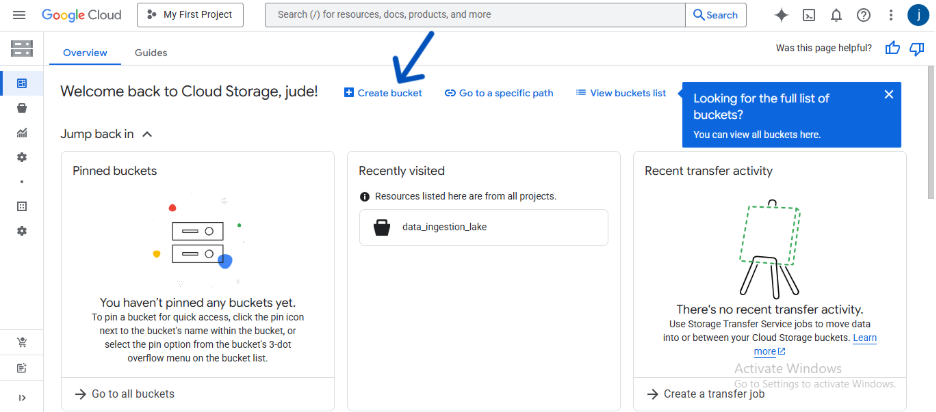
- Choose your desired location and accept the default settings for the other options.
- Click CREATE. A more detailed guide on creating a bucket can be found here.
Create a BigQuery Dataset
A dataset in BigQuery is like a folder or schema that contains your tables.
- In the GCP Console, navigate to BigQuery.
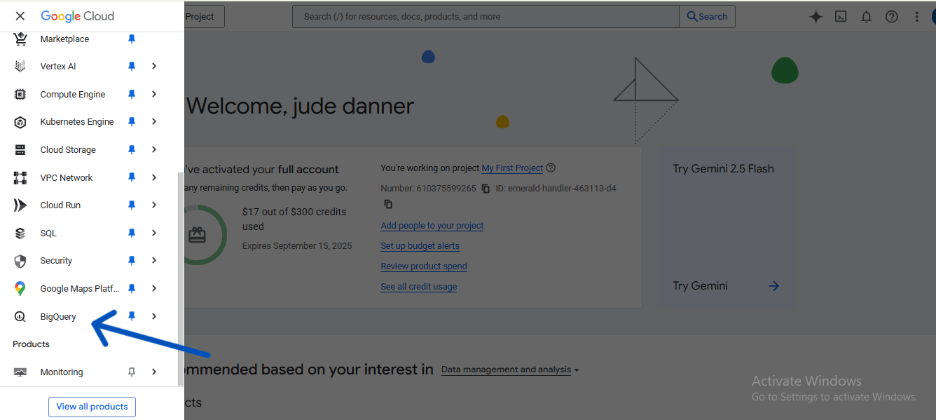
- In the Explorer panel, click the elipses (three-dot menu) next to your project ID and select Create dataset.

- For the Dataset ID, enter an appropriate name (e.g. covid_data).
- Choose your desired data location. It’s best practice to keep it in the same region as your storage bucket.
- Click CREATE DATASET.

With our storage and destination now ready, we can move on to Cloud Function.
Create and Configure the Cloud Run Function (Cloud Function)
This is the core of our automated pipeline. We will create a Cloud Run Function that holds our Python code. We’ll then set it up to be triggered on a schedule.
Note: As of August 21st, 2024, Google Cloud Function is now Google Cloud Run Function
- In the GCP Console, use the search bar to find and navigate to Cloud Run Functions.

- Click Write a Function.
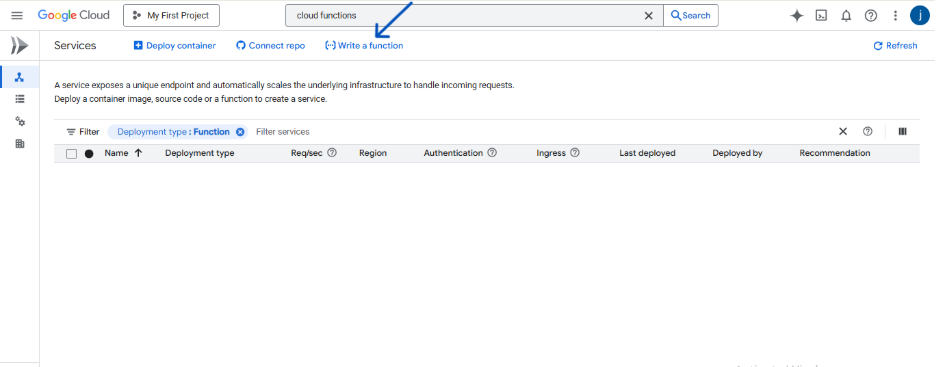
Configure the basic settings:
- Function name: Give it an appropriate name (e.g. ingest-covid-data).
- Region: Choose the same region you used for your bucket and BigQuery dataset.

- Configure the Endpoint URL:
Under the runtime, select Python 3.12 (or your preferred Python 3 version)
Configure the trigger:
- Under the Trigger section, select Cloud Pub/Sub trigger. We will connect this to a scheduler in a later step.
- A Topic ID will be suggested for you (e.g., ingest-covid-data-topic). You can leave this as is. Click CREATE A TOPIC.
- Leave the other settings as they are and click SAVE TRIGGER.
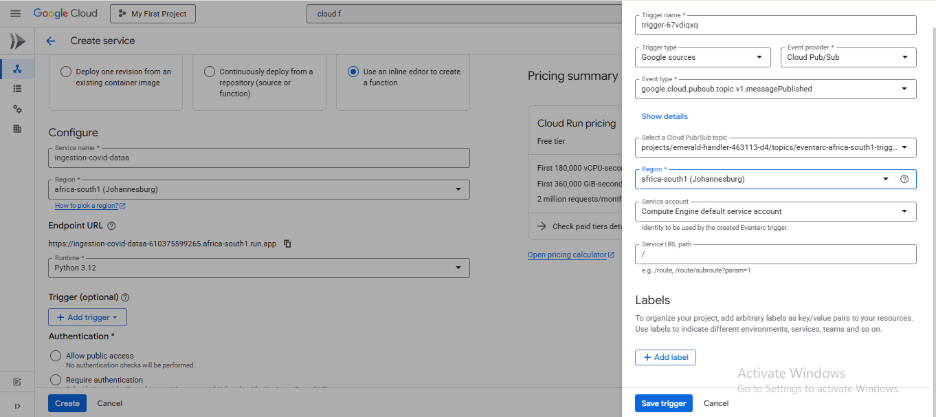
Leave everything else as is and click on CREATE, then wait for a few minutes for your function to be created.
Once your function has been created, you’ll see your code editor showing two files: main.py (for our Python code) and requirements.txt (for our library dependencies).
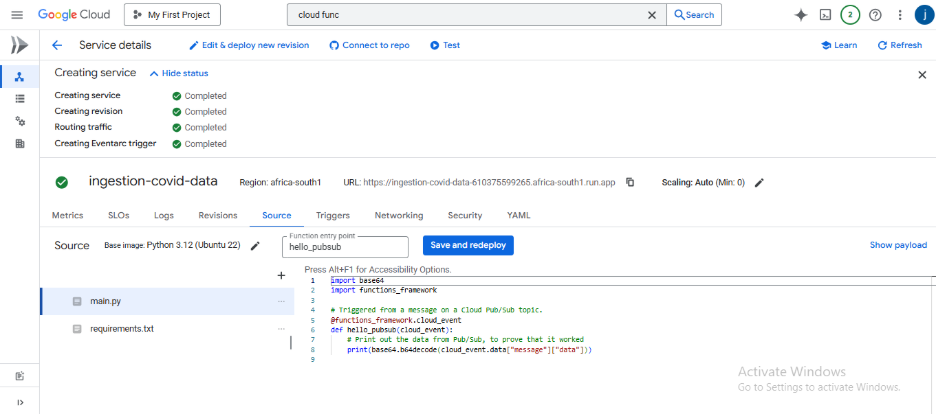
Leave this page open. We will now add the necessary code to these files in the next step.
Write the Ingestion Code
Now, we’ll write the Python code that performs the core logic of our pipeline. This involves fetching the data, cleaning it slightly for BigQuery compatibility, staging it in Cloud Storage, and finally loading it into our BigQuery table.
Add the Library Dependencies
First, in the requirements.txt file in the inline editor, add the Python libraries our function needs to run.
# requirements.txt
pandas
google-cloud-storage
gcsfs
pandas-gbq
Write the Main Python Script
Next, replace the boilerplate code in the main.py file with the following script. Be sure to replace the placeholder values in the “Configuration variables” section with your actual GCP project ID, bucket name, and dataset ID.
main.py
import pandas as pd
from google.cloud import storage
from google.cloud import bigquery
import base64
import json
from cloudevents.http import CloudEvent
def ingest_covid_data(cloud_event: CloudEvent):
"""
Cloud Function to ingest COVID-19 data, upload to GCS,
and load into BigQuery. Triggered by a Pub/Sub message.
"""
# --- Configuration variables (can be overridden by Pub/Sub message) ---
default_source_url = "https://ourworldindata.org/grapher/daily-cases-covid-region.csv?v=1&csvType=full&useColumnShortNames=true"
bucket_name = "covid19_data_ingestion"
gcs_file_path = "raw_data/owid-covid-data.csv"
project_id = "emerald-handler-463113-d4"
dataset_id = "covid19_data"
table_id = "daily_covid_stats"
print("--> Pipeline started.")
# 1. Decode and parse the Pub/Sub message payload
source_url = default_source_url
try:
if cloud_event.data:
pubsub_message_bytes = base64.b64decode(cloud_event.data)
pubsub_message_str = pubsub_message_bytes.decode('utf-8')
message_data = json.loads(pubsub_message_str)
source_url = message_data.get('source_url', default_source_url)
print(f"--> Using source URL from Pub/Sub message: {source_url}")
else:
print(f"--> No data found in Pub/Sub message payload. Using default URL.")
except (base64.binascii.Error, UnicodeDecodeError, json.JSONDecodeError) as e:
print(f"Error decoding or parsing Pub/Sub message: {e}. Using default URL.")
source_url = default_source_url
# 2. Fetch data from the source URL using storage_options
try:
print(f"--> Fetching data from {source_url}...")
# Use the storage_options to set the User-Agent header
df = pd.read_csv(source_url, storage_options={'User-Agent': 'Our World In Data data fetch/1.0'})
print("--> Data fetched successfully.")
except Exception as e:
print(f"Error fetching data: {e}")
# Return a non-None value on failure
return f"Failed: {e}"
# 3. Clean column names for BigQuery compatibility
df.columns = df.columns.str.lower().str.replace('[^0-9a-zA-Z_]', '_', regex=True)
# 4. Upload the raw data to Google Cloud Storage (Staging)
try:
print(f"--> Uploading raw data to GCS bucket: {bucket_name}...")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(gcs_file_path)
blob.upload_from_string(df.to_csv(index=False), 'text/csv')
print("--> Raw data uploaded successfully.")
except Exception as e:
print(f"Error uploading to GCS: {e}")
# Return a non-None value on failure
return f"Failed: {e}"
# 5. Load the DataFrame into BigQuery
try:
print(f"--> Loading data into BigQuery table: {project_id}.{dataset_id}.{table_id}...")
df.to_gbq(
destination_table=f"{dataset_id}.{table_id}",
project_id=project_id,
if_exists="replace"
)
print("--> Data loaded into BigQuery successfully.")
except Exception as e:
print(f"Error loading to BigQuery: {e}")
# Return a non-None value on failure
return f"Failed: {e}"
print("--> Pipeline finished successfully.")
return "Success: Data pipeline completed."
Deploy the Function
Once you’ve added the code to both files and updated your configuration variables:
- Make sure the Entry point field below the editor is set to the name of our Python function (in this case ingest_covid_data).
- Click the DEPLOY button.

Deployment will take a few minutes. GCP will install the required libraries and provision the necessary infrastructure for your function. Once it’s done, you’ll see a green checkmark next to your function’s name.
Schedule the Pipeline ⏰
Our function is deployed, but it only runs when we test it manually. The final step is to create a schedule to trigger it automatically every day. We’ll use Cloud Scheduler for this.
- In the GCP Console, navigate to Cloud Scheduler.
- Click CREATE JOB.
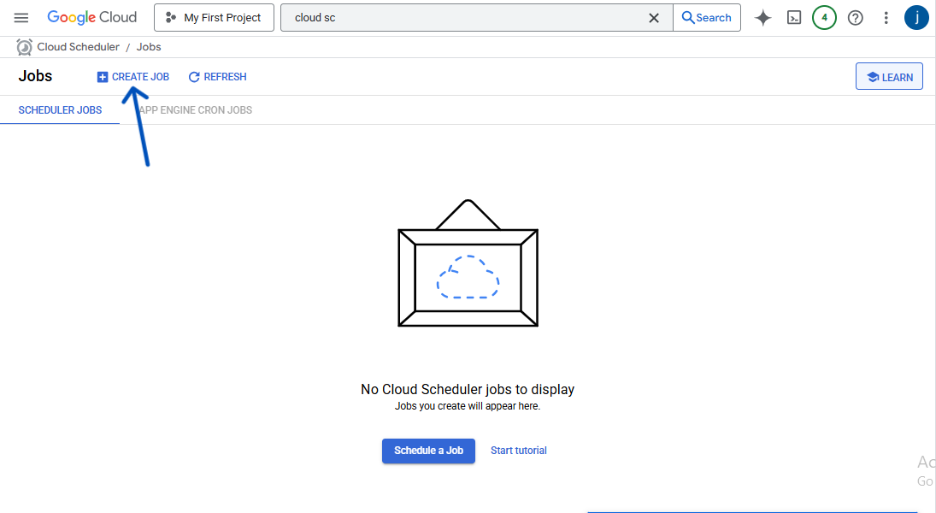
Fill in the job details:
- Name: Give it a name (e.g. daily-covid-ingestion-trigger).
- Frequency: Set the schedule using unix-cron format. To run it at 1 AM every day, enter 0 1 * * *.
- Timezone: Select your preferred timezone (e.g., GMT+01:00 London, United Kingdom Time).

Configure the target:
- Target type: Select Pub/Sub.
- Topic: Select the Pub/Sub topic that was created with your Cloud Function (e.g., ingest-covid-data-topic).
- Message body: You can write down a short descriptive message.
4. Click CREATE.

That’s it! Your pipeline is now fully automated. Cloud Scheduler will send a message to your Pub/Sub topic every day at 1 AM, which will trigger your Cloud Function to run and load the latest data.
Common Pitfalls and Troubleshooting
If you run into issues, here are a few common things to check:
- Permissions Errors: The most common issue. If your function fails, check its logs. If you see a 403 Forbidden error, it means the function’s service account doesn’t have the right permissions. Go to IAM & Admin and ensure the service account has roles like Cloud Functions Invoker, Storage Object Admin, and BigQuery User.
- Dependency Issues: A ModuleNotFoundError in the logs means a library was missing. Double-check that all required libraries (pandas, pandas-gbq, etc.) are correctly listed in your requirements.txt file.
- URL Validity: Ensure the URL is the correct one for the dataset, using a wrong one will cause the pipeline to fail.
- Function Timeouts: By default, a Cloud Function times out after 60 seconds. If you’re working with a very large file, it might take longer. You can increase the timeout by editing your function and changing the value in the Timeout field under the “Runtime” settings.
Conclusion and Next Steps
Congratulations! You have successfully built and deployed a fully automated, serverless data ingestion pipeline on Google Cloud. Using a Cloud Function triggered by Cloud Scheduler, you created a cost-effective and reliable system that fetches fresh data daily, stages it in Cloud Storage, and loads it into BigQuery for analysis.
You’ve seen first hand how modern cloud tools can handle complex data workflows with remarkable simplicity and efficiency. This serverless pattern is a powerful tool in any data engineer’s toolkit.
🚀 Next Steps
Ready to take this project further? Here are some ideas:
- Add Notifications: Modify the Cloud Function to use the SendGrid API or another email service to send you a notification email when the pipeline succeeds or fails.
- Introduce Transformations: Before loading the data into BigQuery, add more data cleaning or transformation steps using Pandas within your function. For example, you could convert date columns to the correct data type or create new columns based on existing data.
- Explore Terraform: For a more advanced challenge, try deploying this entire infrastructure (Bucket, BigQuery Dataset, and Cloud Function) using Terraform, an Infrastructure as Code (IaC) tool.